数据结构-排序(五)快速排序
1、算法思想
算法思想:在待排序表L[1…n]中任取⼀个元素pivot作为枢轴(或基准,通常取首元素),通过⼀趟排序将待排序表划分为独立的两部分L[1…k-1]和L[k+1…n],使得L[1…k-1]中的所有元素小于pivot,L[k+1…n]中的所有元素大于等于pivot,则pivot放在了其最终位置L(k)上, 这个过程称为⼀次“划分”。然后分别递归地对两个子表重复上述过程,直至每部分内只有⼀个元素或空为止,即所有元素放在了其最终位置上。
举个栗子🌰 ,将 4 1 6 2 9 3 进行快速排序
首先在这个序列中随便找一个基准数(pivot)。为了方便,通常让第一个数 4 作为基准数。接下来,需要将这个序列所有比基准数大的数放在4的右边,比准数小的数放在 4 的左边,即:
3 1 2 4 9 6
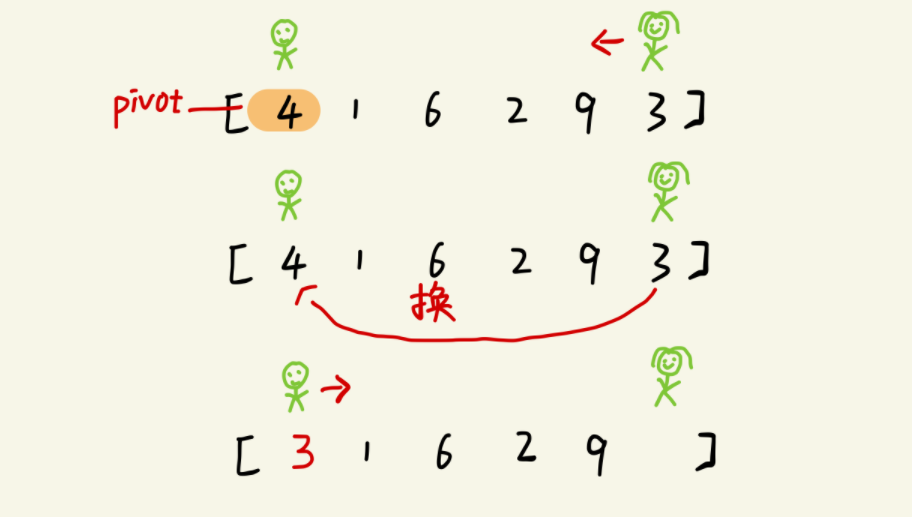
在初始状态下,数字4在序列的第一位。我们需要将 4 挪到中间的一个位置,假设这个位置是k。现在需要找这个k,并且以k为分界点,左边的数都小于等于4,右边的数都是大于等于4。
分别从初始序列“4 1 6 2 9 3”两端开始勘测。定义变量pivot存储基准数4,然后先从左往右找一个小于4的数,找到后,将其与放到左边,即放到4,4放到6,再从右往左找一个大于4的数,然后将其放到上一个小于基准数4的位置,即上个6,现在4的位置。这里可以用两个变量low 和 high,分别指向序列最左边和最右边(即两个哨兵)。刚开始的时候 “哨兵low” 指向序列最左边(即i=1),指向数字4,“哨兵high”指向序列最右边(即j=6),指向数字3。
哨兵high开始出动。因为基准数设置为最左边的数。哨兵high一步一步向左挪动(即high–),直到找到一个小于4的数停下来,哨兵j停在了数字3上。接下来哨兵high与哨兵low交换
交换后序列如下
3 1 6 2 9 4
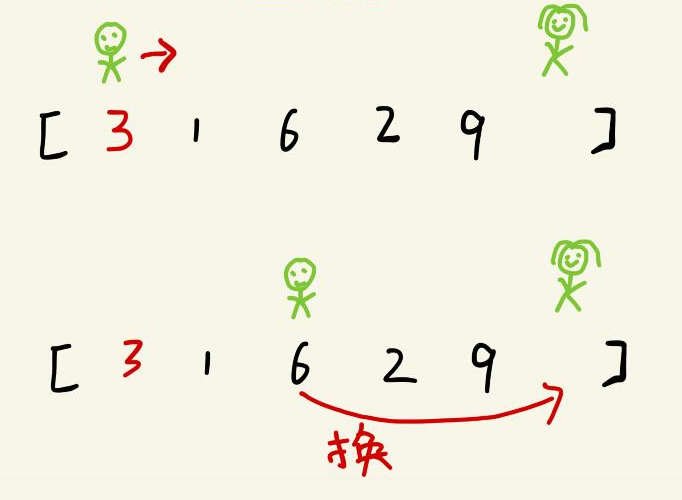
接下来哨兵low再一步一步向右挪动(即low++),直到找到一个大于4的数停下来。哨兵low停在了数字6上。哨兵low与哨兵high交换
交换后序列如下
3 1 4 2 9 6
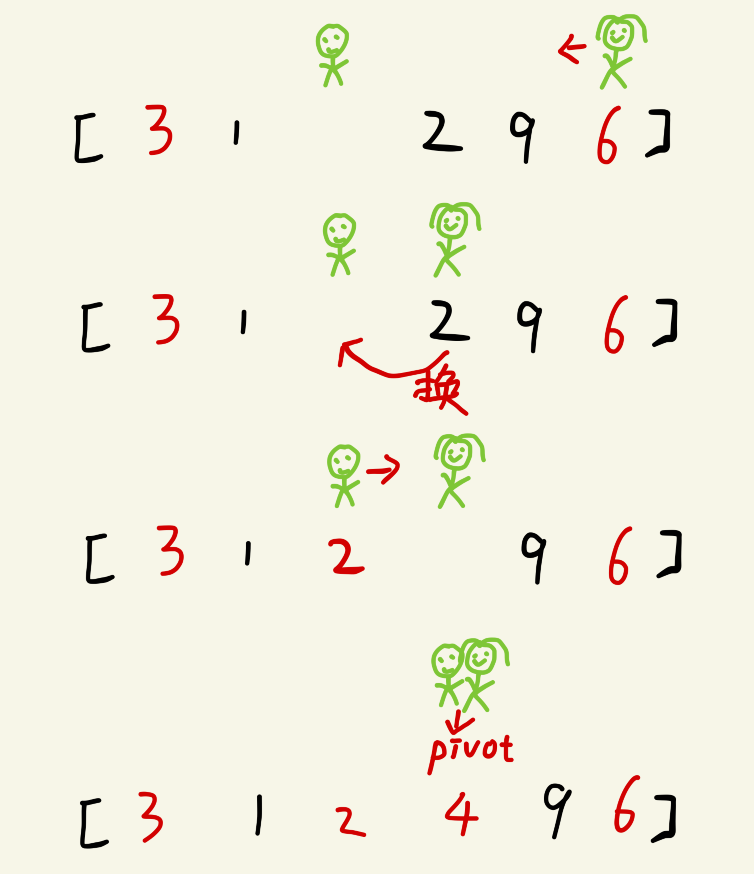
然后哨兵high,哨兵low继续移动直到相遇。然后将pivot赋值给哨兵
相遇后与基准数交换后的序列为:
3 1 2 4 9 6
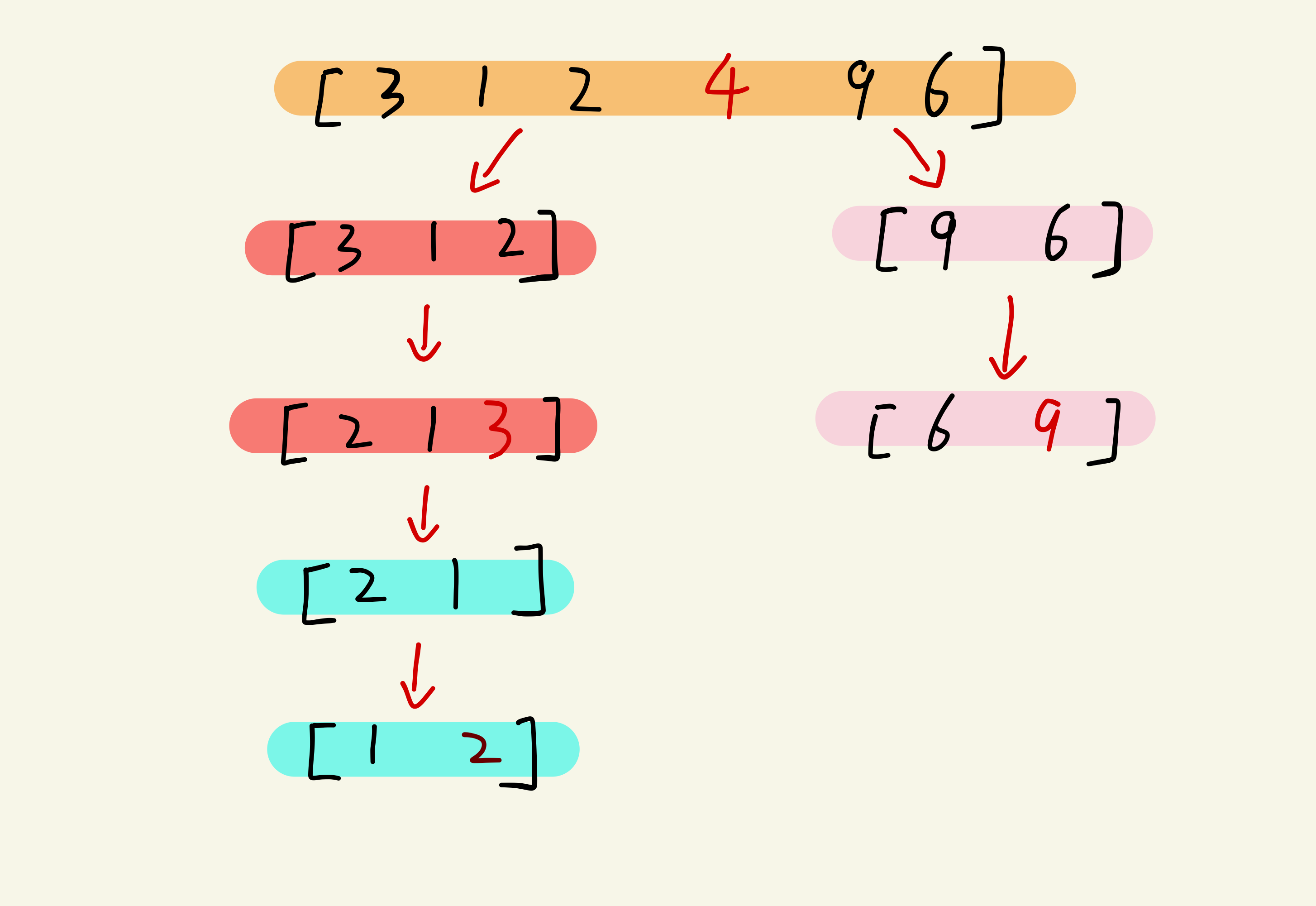
现在基准数4已经归位,此时,我们以4(基准数)为分界点拆分为两个序列,左边为“3 1 2”,右边序列为“9 6”。接下来我们按照第一轮勘测的方法继续处理。直到不可拆分出新的子序列为止。
2、代码实现
1 |
|
3、算法效率分析
把n个元素组织成⼆叉树,⼆叉树的层数就是递归调用的层数
第⼀层QuickSort处理后:n个结点的⼆叉树最小高度 = ⌊log2n⌋ + 1 ;最大高度 = n1、空间复杂度: O(递归层数)
最好空间复杂度:$O(log_2n)$
最坏空间复杂度:$O(n)$
2、时间复杂度 O(n*递归层数)
最好时间复杂度:$O(nlog_2n)$ 每次选的枢轴元素都能将序列划分成均匀的两部分
最坏时间复杂度:$O(n^2)$ 若序列原本就有序或逆序,则时、空复杂度最⾼(可优化,尽量选择可以把数据中分的枢轴元素。)
快速排序是所有内部排序算法中平均性能最优的排序算法
3、稳定性:不稳定
4、快速排序算法优化思路:尽量选择可以把数据中分的枢轴元素。
eg:①选头、中、尾三个位置的元素,取中间值作为枢轴元素;②随机选⼀个元素作为枢轴元素


