数据结构-排序(七)堆排序
若n个关键字序列L[1…n] 满⾜下面某⼀条性质,则称为堆(Heap) :
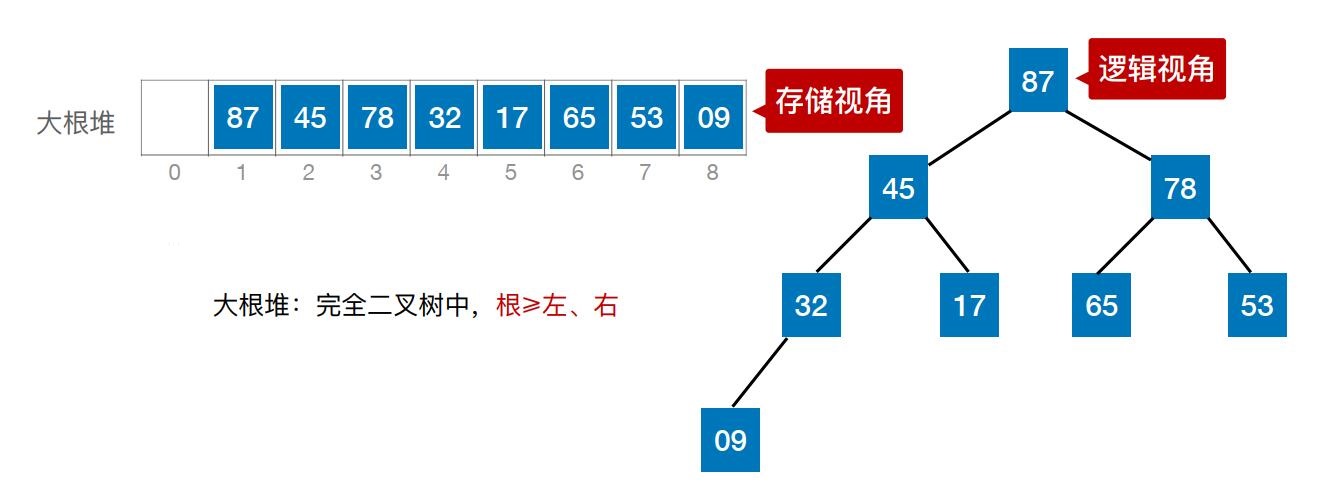
① 若满足:L(i) ≥ L(2i)且L(i) ≥ L(2i+1) (1 ≤ i ≤n/2 ) —— 大根堆(大顶堆)
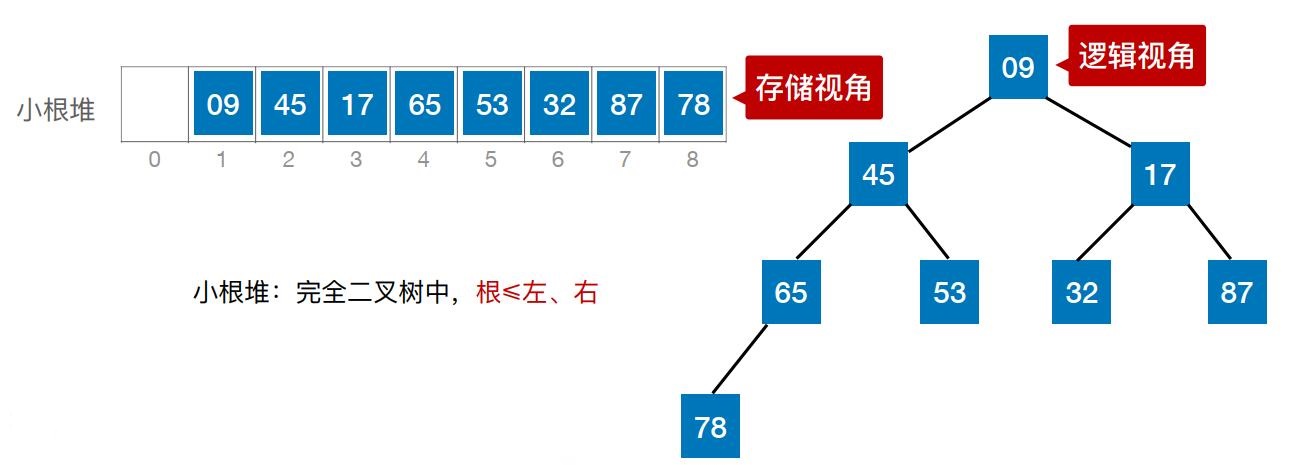
② 若满足:L(i) ≤ L(2i)且L(i) ≤ L(2i+1) (1 ≤ i ≤n/2 ) —— 小根堆(小顶堆)
1、建立大根堆
大根堆: 根 ≥ 左、右
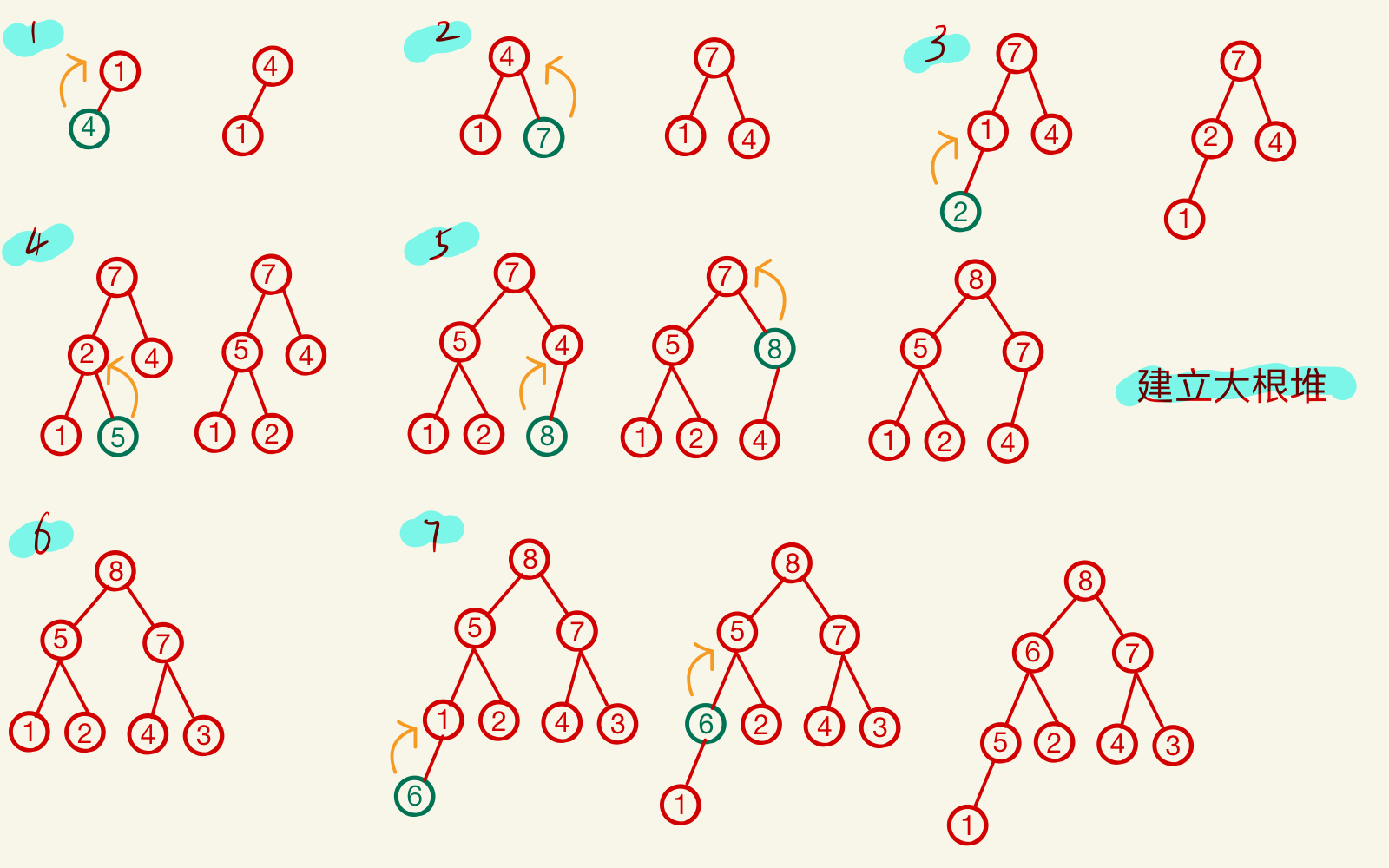
思路:把所有非终端结点都检查⼀遍,是否满足大根堆的要求,如果不满足,则进行调整。检查当前结点是否满足根≥左、右。若不满足,将当前结点与更大的⼀个孩子互换。若元素互换破坏了下⼀级的堆,则采用相同的方法继续往下调整(小元素不断“下坠”)
在顺序存储的完全⼆叉树中, 非终端结点编号 i ≤ ⌊ n / 2 ⌋
2、基于大根堆排序
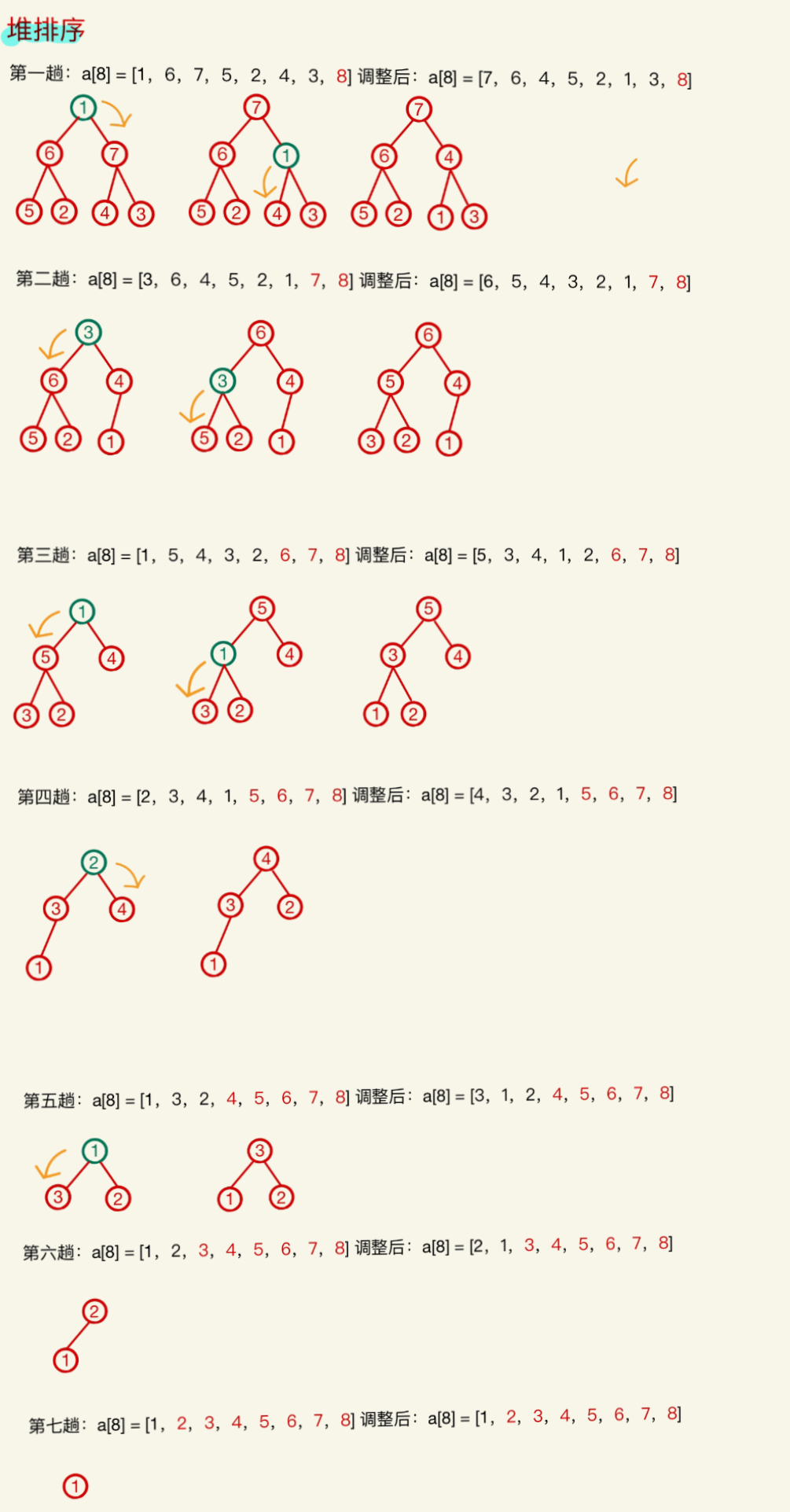
堆排序:每⼀趟将堆顶元素加入有序子序列(与待排序序列中的最后⼀个元素交换)
选择排序:每⼀趟在待排序元素中选取关键字最大的元素加入有序子序列并将待排序元素序列再次调整为大根堆(小元素不断“下坠”)
图解示例请看6。
3、堆的插入和删除
1、插入
对于小根堆,新元素放到表尾,与父节点对比,若新元素比父节点更小,则将⼆者互换。新元素就这样⼀路“上升”,直到无法继续上升为止。
每次“上升”调整需要对比一次关键字
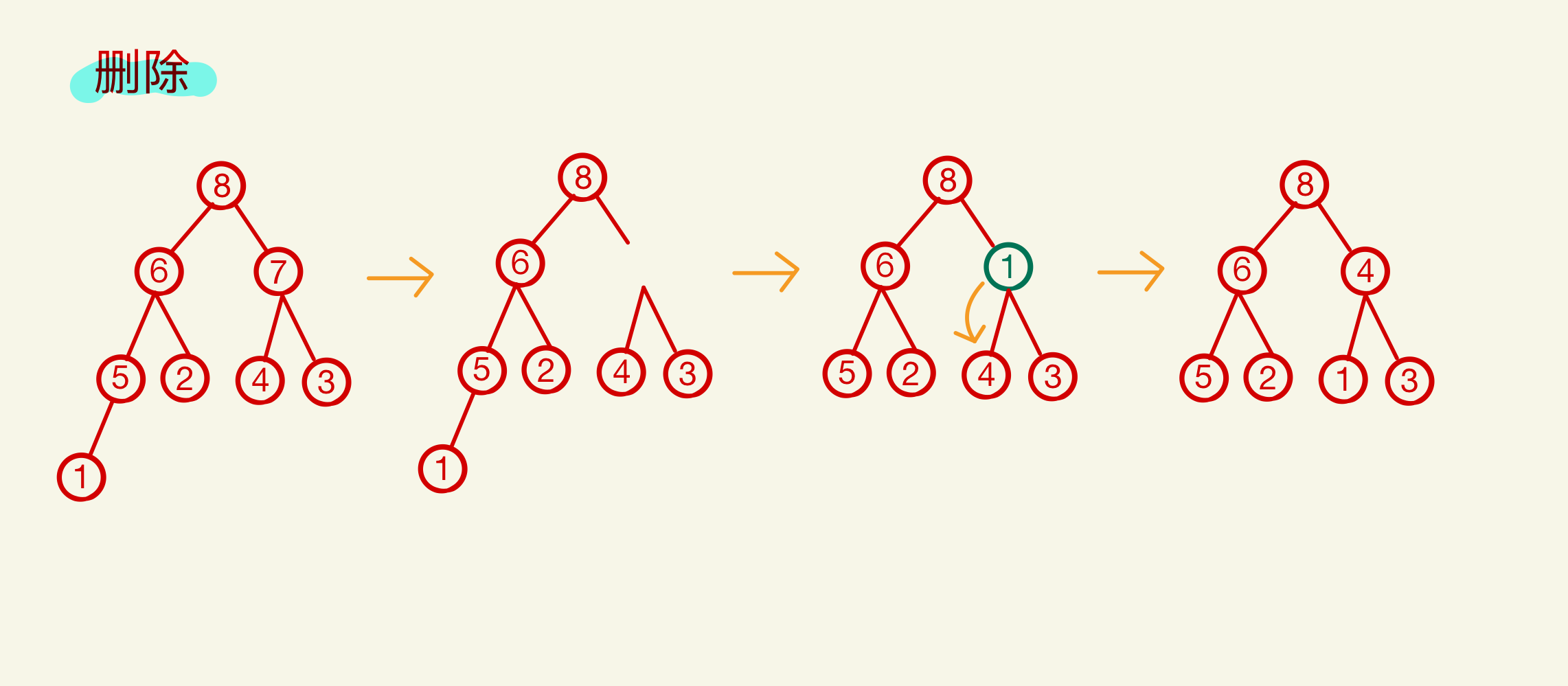
2、删除
被删除的元素用堆底元素替代,然后让该元素不断“下坠”,直到无法下坠为止。
每次“下坠”调整可能需要对比一次关键字,也可能需要对比两次关键字
4、代码实现
1 |
|
5、算法效率分析
1、建堆过程时间复杂度
结论:⼀个结点,每“下坠”⼀层,最多只需对比关键字2次
若树高为h,某结点在第 i 层,则将这个结点向下调整最多只需要“下坠” h-i 层,关键字对比次数不超过 2(h - i)
n个结点的完全二叉树树高 $h=⌊ log_2n ⌋ + 1$第 i 层最多有 $2^{i-1}$ 个结点,而只有第 1 ~ (h-1) 层的结点才有可能需要“下坠”调整。
将整颗树调整为大根堆,关键字对比次数不超过4n
$\sum_{i=h-1}^{1}2^{i-1}*2(h-i)$
$=\sum_{i=h-1}^{1}2^i(h-i)$
$= \sum_{j=1}^{h-1}2^{h-j}*j $
$\le 2n\sum_{j=1}^{h-1}\frac{j}{2^j}$
$\le 4n$
建堆的过程,关键字对比次数不超过4n,建堆时间复杂度=O(n)
2、排序过程时间复杂度
根节点最多“下坠” h-1 层,每下坠⼀层,而每“下坠”⼀层,最多只需对比关键字2次,
因此每⼀趟排序复杂度不超过 $O(h) = O(log_2n)$。共n-1 趟,总的时间复杂度 =$O(nlog_2n)$
3、堆排序
堆排序的空间复杂度:O(1)
堆排序的时间复杂度:$O(n) + O(nlog_2n) = O(nlog_2n)$
4、稳定性 : 不稳定
6、示例
示例:将数组a[8] = [1,4,7,2,5,8,3,6]建成大根堆。画出建堆过程。并画出堆排序过程
数组插入建堆过程图如下:
堆排序示例图如下:
删除示例图如下: